因為疫情,這學習開始學校要求大家每天都要在九點前到學校網站上傳體溫,我覺得非常麻煩。
動點,果沒傳要被記警告!?
這種麻煩的要求我當然是不會每天乖乖上傳的,於是我做了一個小爬蟲來幫我自動上傳體溫。
本來每天用的好好,但有一天我發現爬蟲沒有上傳成功,於是我只能手動上傳,但當我打開網站要上傳時,我看到了令我無比傻眼的畫面..........????????!
說實話我看到這個東東我有點驚訝又覺得很好笑??,於是我就開始想解決它。
使用語言:python
使用套件
import requests
from bs4 import BeautifulSoup, element
from selenium import webdriver
import selenium
import time
首先,我用requests和把網站爬下來,然後丟到BeautifulSoup裡剖析。
url='https://webap1.kshs.kh.edu.tw/kshsSSO/publicWebAP/bodyTemp/index.aspx'
r=requests.get(url)
soup=BeautifulSoup(r.text,'lxml')
再來,我的任務是讓電腦自動判斷驗證的數字,並勾相應的選項。
取得驗證數字有問題的方式
我把BeautifulSoup剖析後的網頁,用find$=(id=''ContentPlaceHolder1_lb)的方式找出html中顯示驗證數字的span(區域)並將tag_verification_num.string(驗證數字)存到tag_verification_num變數中。
但問題來了,當我把tag_verification_num這個變數print出來時,它的值是null。
解決方法
把BeautifulSoup剖析後的網頁,用find$=(id='ContentPlaceHolder1_lb')的方式找出html中顯示驗證數字的span(區域)並將tag_verification_num.string(驗證數字)存到tag_verification_num變數後,將它轉成str(字串型態),在這裡我發現這個span轉成字串後的第65個數字就是我要的驗證數字
於是我將其存到變數中,以便之後使用。
tag_verification_num=soup.find(id='ContentPlaceHolder1_lbN')
num_verification=str(tag_verification_num)
num_verification=num_verification[65]
現在我已經取得驗證數字了,接下來我需要取得每個驗證選項的數字。
因為驗證選項的html結構是用span標籤把input選項和顯示選項數字的label包起來。

所以我先用find.(id='ContentPlaceHolder1_RadioButtonList1')找到input和label的父標籤span,
存到tag_verification變數中,再用tag_verification.find_all('input')找到所有span裡的input標籤。
tag_verification=soup.find(id='ContentPlaceHolder1_RadioButtonList1')
tag_verification_input=tag_verification.find_all('input')
錯誤取得選項值的方式
用tag_verification.find_all('input')取得所有span裡的input標籤後,再用for i in tag_verification_input:存取每個input標籤的value值,但是這邊我遇到跟前面很像的問題,
就是當我用print(i.value)把它print出來的值是null。
解決方法
這裡也可以用跟上面一樣的方式,把input標籤轉成字串型態,在找到value的值是字串中的第幾個字元,
這樣就可以取得驗證選項的數字。
tag_verification=soup.find(id='ContentPlaceHolder1_RadioButtonList1')
tag_verification_input=tag_verification.find_all('input')
for i in tag_verification_input:
num_input=str(i)
num_input[121]//驗證選項的數字
現在我有了驗證的數字,也有了每個選項的數字,那我現在要做的是判斷哪一個選項的數字等於驗證數字。
我在for i in tag_verification_input:裡面加上判斷式,
來判斷i轉成字串後的第121個字元(驗證選項的數字)是否等於num_verification(驗證數字),
for i in tag_verification_input:
num_input=str(i)
if num_verification==num_input[121]:
//填報體溫
我已經知道對應到驗證數字的input標籤了,現在我要知道這個input標籤的name屬性,才能用find_element_by_name()控制webdriver勾選正確選項。
如果用最直覺的方法num_input=i.name,那num_input的值一樣會是null,所以還是要把i轉成字串,
然後num_input[57:99]存取第59~99之間字元,這個就是i的name。
得到input標籤的name之後,就可以控制webdriver勾選正確選項了~
import requests
from bs4 import BeautifulSoup, element
from requests.models import Response
from selenium import webdriver
import selenium
import time
url='https://webap1.kshs.kh.edu.tw/kshsSSO/publicWebAP/bodyTemp/index.aspx'
r=requests.get(url)
soup=BeautifulSoup(r.text,'lxml')
driver=webdriver.Chrome("./chromedriver")
driver.get(url)
tag_verification_num=soup.find(id='ContentPlaceHolder1_lbN')
num_verification=str(tag_verification_num)
num_verification=num_verification[65]
def enter_step1():
tag_input = driver.find_element_by_name("ctl00$ContentPlaceHolder1$txtId")
tag_input.send_keys('(身分證字號)')
driver.find_element_by_name("ctl00$ContentPlaceHolder1$btnId").click()
def enter_step2():
driver.find_element_by_name('ctl00$ContentPlaceHolder1$rbType').click()
driver.find_elenent_by_xpath('//*[@id="ContentPlaceHolder1_ddl1"]/option[3]').click()
driver.find_element_by_xpath('//*[@id="ContentPlaceHolder1_ddl2"]/option[3]').click()
driver.find_element_by_xpath('//*[@id="ContentPlaceHolder1_ddl3"]/option[2]').click()
driver.find_element_by_name('ctl00$ContentPlaceHolder1$btnId0').click()
tag_verification=soup.find(id='ContentPlaceHolder1_RadioButtonList1')
tag_verification_input=tag_verification.find_all('input')
for i in tag_verification_input:
num_input=str(i)
print('迴圈外',num_input[121])
if num_verification==num_input[121]:
print('要驗證的數字',num_verification)
print('要輸入的數字',num_input[121])
print('secess\n')
print(i)
print(type(i),'\n')
print(num_input[57:99])
print(type(num_input[57:99]))
print('選取的數字:',num_input[121])
driver.find_element_by_name(num_input[57:99]).click()
enter_step1()
enter_step2()
else:
print('fail')
time.sleep(3)
driver.quit()
2021/4/21學校又再次做出了令我意外的改動.....
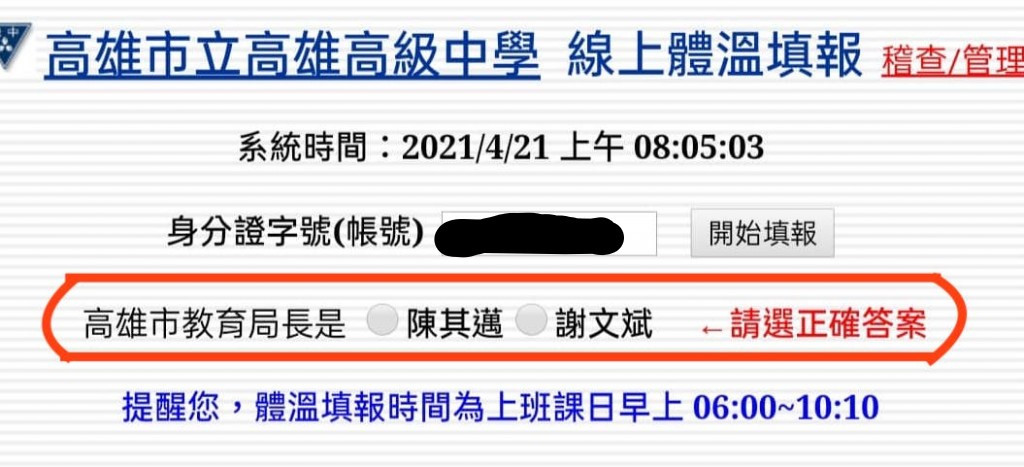
驗證換成了隨機的問題,學校這波操作再次讓我感到驚喜,建議下次驗證改成解微積分。
一開始我心想,學校會放的題目因該都是大眾會到的基本知識,那麼維基百科也一定查得到,所我想用requests和beautifulsoup把題目爬下來,然後再送到維基百科搜尋答案,最後判斷維基百科的答案和網站上選項爬下來的答
案是否相同。
問題:這次驗證方式改版後,我發現已經沒辦法用requests和beautifulsoup選項標籤的任何屬性。
解決方法:能力不足,無解。
問題:
後來我老師建議了我一個可以忽略所有標籤的值,和驗證題目的方法。
就是我發現驗證選項的每個input標籤的id屬性前面都是ContentPlaceHolder1_RadioButtonList1_,
而最後一個數字是選項的編號,比如說:
選項一:ContentPlaceHolder1_RadioButtonList1_0
選項二:ContentPlaceHolder1_RadioButtonList1_1
選項三:ContentPlaceHolder1_RadioButtonList1_2
這樣就只需要按照這個規則一個選項一個選項的試,就可以解決了。
function
為了方便,我把除了驗證之外的操作做成function。
enter_step1()
def enter_step1():
print('step1')
driver.find_element_by_id('ContentPlaceHolder1_txtId').send_keys('(身分證字號)')
driver.find_element_by_id('ContentPlaceHolder1_btnId').click()
enter_step2()
def enter_step2():
print('step2')
driver.find_element_by_id('ContentPlaceHolder1_rbType_1').click()
driver.find_element_by_xpath('//*[@id="ContentPlaceHolder1_ddl1"]/option[3]').click()
driver.find_element_by_xpath('//*[@id="ContentPlaceHolder1_ddl2"]/option[4]').click()
driver.find_element_by_xpath('//*[@id="ContentPlaceHolder1_ddl3"]/option[2]').click()
submit()
def sunmit():
print('submit')
driver.find_element_by_id('ContentPlaceHolder1_btnId0').click()
驗證
首先,我把所有裝有驗證選項的input標籤的id屬性,去掉代表邊好的最後一個數字,然後存到id變數中。
name='ContentPlaceHolder1_RadioButtonList1_'
因為選項的數量每天不一樣,但是經過我的觀察,選項最多只有4個。
所以我用for i in range(3),然後宣告一個變數等於name+iinput_id=name+str(i),就可以利用for迴圈取得每個input標籤的i屬性,再把這個變數放到find_element_by_id()中,每一圈都試一次。
然後因為如果驗證失敗還繼續執行填報體溫的程式碼的話,就會噴error,所以在for迴圈裡面用例外處理
try和except,如果驗證失敗就直接去下一回圈。
因為按下開始填報後,網頁會跳出一個alert說“開始填報”,所以我要switch_to_alert().accept()來確認這個alert。
for i in range(3):
try:
input_id=name+str(i)
print(input_id)
driver.find_element_by_id(input_name).click()
enter_step1()
driver.switch_to_alert().accept()
print('success')
enter_step2()
# sunmit()
except:
print('fail')
# driver.switch_to_alert().accept()
可能的問題:
這樣也不需要擔心,因為如果今天選項只有兩個,卻跑了4個for迴圈,因為如果只有兩個選項,那正確選項也一定在for回圈前兩圈中,程式只要跑到正確選項時,就會直接完成體溫填報。
結論
這樣不管遇到怎樣的驗證問題,都不會影響程式的執行~~
開心。
import requests
from selenium import webdriver
import time
url='https://webap1.kshs.kh.edu.tw/kshsSSO/publicWebAP/bodyTemp/index.aspx'
driver=webdriver.Chrome("./chromedriver")
driver.get(url)
def enter_step1():
print('step1')
driver.find_element_by_id('ContentPlaceHolder1_txtId').send_keys('(身分證字號)')
driver.find_element_by_id('ContentPlaceHolder1_btnId').click()
def enter_step2():
print('step2')
driver.find_element_by_id('ContentPlaceHolder1_rbType_1').click()
driver.find_element_by_xpath('//[@id="ContentPlaceHolder1_ddl1"]/option[3]').click()
driver.find_element_by_xpath('//[@id="ContentPlaceHolder1_ddl2"]/option[4]').click()
driver.find_element_by_xpath('//[@id="ContentPlaceHolder1_ddl3"]/option[2]').click()
def sunmit():
print('submit')
driver.find_element_by_id('ContentPlaceHolder1_btnId0').click()
id='ContentPlaceHolder1_RadioButtonList1_'
for i in range(3):
try:
input_id=name+str(i)
print(input_id)
driver.find_element_by_id(input_name).click()
enter_step1()
driver.switch_to_alert().accept()
print('success')
enter_step2()
sunmit()
except:
print('fail')
time.sleep(5)
driver.quit()
 the_shy_of_bush
the_shy_of_bush

